AvidBeam’s Visual Language Model: Enterprise AI That Thinks Like the Operations Team
- December 18, 2025
- Posted by:
- Categories: Articles, Articles & Blogs
Visual language models represent a technological shift in how organizations extract intelligence from visual data, combining computer vision capabilities with natural language understanding to process video, image, and text. And this multimodal approach enables businesses/organizations to query surveillance systems conversationally and receive detailed insights without requiring technical expertise in data analysis or complex search parameters.
What Are Visual Language Models?
Visual language models function as AI systems built by combining large language models with vision encoders and granting the ability to process visual information alongside textual data.
The architecture consists of components working in coordination. A vision encoder, typically a CLIP-based model with transformer architecture trained on millions of image-text pairs, associates visual and textual information. The projector translates vision encoder output into formats that language models can interpret, functioning as image tokens through either simple linear layers or complex cross-attention mechanisms.
Training occurs through pretraining stages that align the vision encoder, projector, and language model to interpret text and image inputs cohesively using a large corpus of image-caption pairs and interleaved image-text data. Supervised fine-tuning follows, teaching the system how to respond to user prompts through example prompts with expected responses, such as describing images or counting objects in frames.
Why Are Vision Language Models Important?
Traditional computer vision models operated within constraints that limited their practical applications for businesses requiring flexibility. The convolutional neural network-based systems handled specific tasks but couldn’t adapt when use cases changed or required new classes without expensive retraining processes involving extensive image collection and labeling. Visual language models deliver capabilities that address these limitations:
- Zero-shot performance on vision tasks, including visual question-answering, classification, and optical character recognition, without task-specific training.
- Flexible application across nearly any use case by simply changing text prompts rather than retraining entire models.
- Natural language understanding that enables non-technical personnel to interact with sophisticated analytics systems.
- Foundation model power, combining CLIP and large language models for both vision and language capabilities.
- Cost efficiency by eliminating the time-consuming, expensive process of collecting, labeling, and retraining models for each new requirement.
Users interact with visual language models similarly to language models, supplying text prompts interleaved with images to generate text output. The open-ended input prompts allow users to instruct systems to answer questions, summarize content, explain visual elements, or reason with images and maintain conversational context across multiple queries.
Learn more about: Heat map analysis in Video Analytics
Generative AI and Video Analytics: The Technological Convergence
Systems using technologies like ChatGPT, DeepSeek, and Gemini search video clips for specific segments, extract and summarize critical information, and analyze tone of voice and emotion in advanced implementations.
The integration operates through several processing stages that convert surveillance camera footage into actionable intelligence. Data preparation converts video content into formats suitable for AI processing, followed by feature extraction that identifies people, objects, actions, and movements within each frame. Pattern identification reveals how these elements relate across frames, and generative AI models produce summaries and insights from the analyzed content.
|
Learn more about: AI Video Analytics
AvidBeam’s Visual Language Model Features
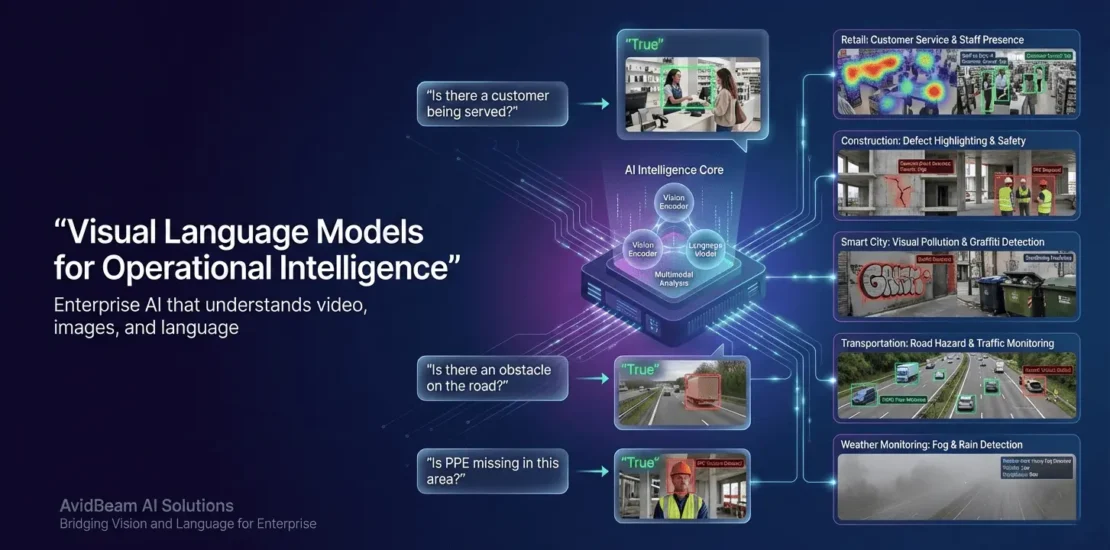
AvidBeam‘s vision language model operates through simple query-response mechanisms that enable personnel to extract insights from video surveillance without technical expertise. The system processes natural language questions and returns binary true/false responses or detailed contextual information based on visual analysis.
1. Retail Intelligence Through Conversational Queries
AvidBeam VLM transforms retail operations by monitoring staff presence, customer behavior, and store organization through direct questions. Query Example:
- User Inquiry: “Is there a customer being served at the counter in this image?”
- System Response: True if staff is present, False if not
Operational Benefits:
- Assess service quality across multiple locations without reviewing hours of footage manually.
- Obtain real-time insights on customer service delivery and queue management.
- Evaluate staffing adequacy through straightforward questions.
- Eliminate the need for specialized training in video analytics software.
2. Structural Compliance Detection for Construction Quality
Construction and infrastructure projects leverage AvidBeam VLM to detect structural defects, alignment issues, and material quality compliance through targeted queries. Query Example:
- User Inquiry: “Is there any honeycombing detected in this concrete work?”
- System Response: True if honeycombing is detected, False if not
Applications for Quality Assurance:
- Identify construction defects that compromise structural integrity.
- Flag areas requiring immediate remediation or further inspection.
- Process visual documentation systematically across work sites.
- Maintain consistent inspection standards throughout construction phases.
3. Visual Pollution Management
Municipal operations leverage AvidBeam VLM to maintain urban cleanliness standards through automated detection of aesthetic violations.
Query Example:
- User Inquiry: “Is there any visual pollution detected in the area?”
- System Response: True if visual pollution is detected, False if not
Operational Benefits:
- Identify graffiti, illegal dumping, and deteriorating infrastructure automatically.
- Enable rapid deployment of cleaning crews to specific locations.
- Supplement citizen reporting mechanisms with continuous automated monitoring.
- Process camera feeds from street-level surveillance networks systematically.
- Ensure consistent aesthetic standards across urban environments.
4. Road Hazard Detection
Transportation departments enhance road safety through continuous monitoring that identifies obstacles requiring immediate response.
Query Example:
- User Inquiry: “Is there any obstacle detected on the road?”
- System Response: True if obstacles are detected, False if not
Operational Benefits:
- Identify debris, stalled vehicles, and construction materials on roadways.
- Trigger immediate dispatch of emergency services or maintenance crews.
- Monitor traffic camera networks continuously for collision risks.
- Support analysis of hazard frequency patterns across road segments.
- Enable rapid response to conditions causing traffic disruption.
5. Weather Condition Monitoring
AvidBeam VLM detects hazardous weather conditions affecting road safety and operational decisions through real-time visibility assessment.
Query Example:
- User Inquiry: “Is the weather foggy today?”
- System Response: True if the weather is foggy, False if not
Operational Benefits:
- Activate fog warning systems and adjust speed limits based on visibility conditions.
- Deploy additional traffic management resources during reduced visibility periods.
- Detect rain, snow, and dust storms affecting transportation safety.
- Supplement meteorological service data with location-specific visual confirmation.
- Support operational decisions for infrastructure operations and outdoor work activities.
All in All
AvidBeam‘s vision language model integration exemplifies the evolution through solutions that enable personnel at all technical levels to interact with surveillance systems conversationally, receiving detailed insights that support better decisions, enhance security, improve customer experiences, and operate more efficiently.
As these technologies continue advancing through enhanced behavior prediction capabilities, seamless integration with access control and building management systems, and greater privacy protection through advanced anonymization techniques, vision language models establish themselves as infrastructure supporting operational intelligence across industries worldwide.
Learn more about: Loitering Detection System